Fine-tuning Asclepio-8B and Qwen2.5-VL-3B: Medical Reasoning and Screenshot-to-Code with LoRA
16 min read
fine-tuningLoRAmedical-aimultimodalVLMdeepseek-r1qwencode-generationhuggingface
LLMs or Large Language Models are artificial intelligence models trained on gigantic amounts of text such as Wikipedia, Reddit or any other open source of text. All these models are trained for a single task: predicting the next word or token. And what is a token? They are words, sub-words or letters represented numerically through an ID assigned during the training of these models, for example:
The sentence: "The cat is playing in the yard", for a language model can be this in tokens:
| Tokens (Words separated) | Token IDs (Numeric representation) |
|---|---|
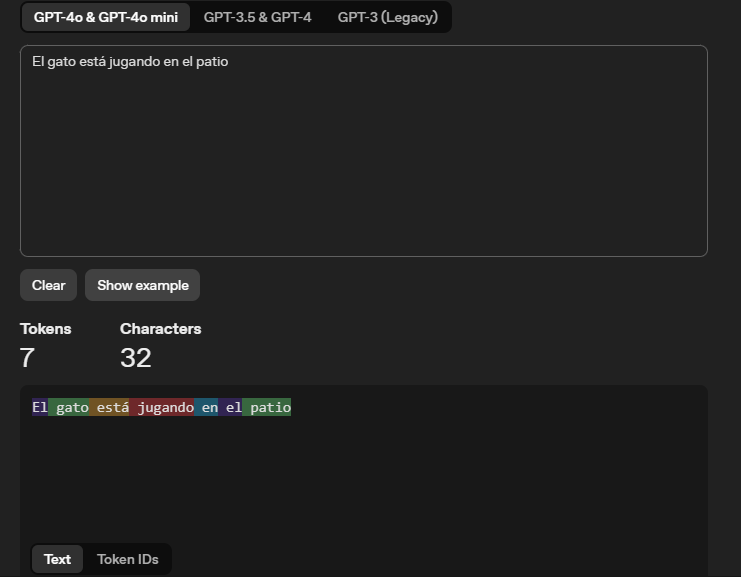 | 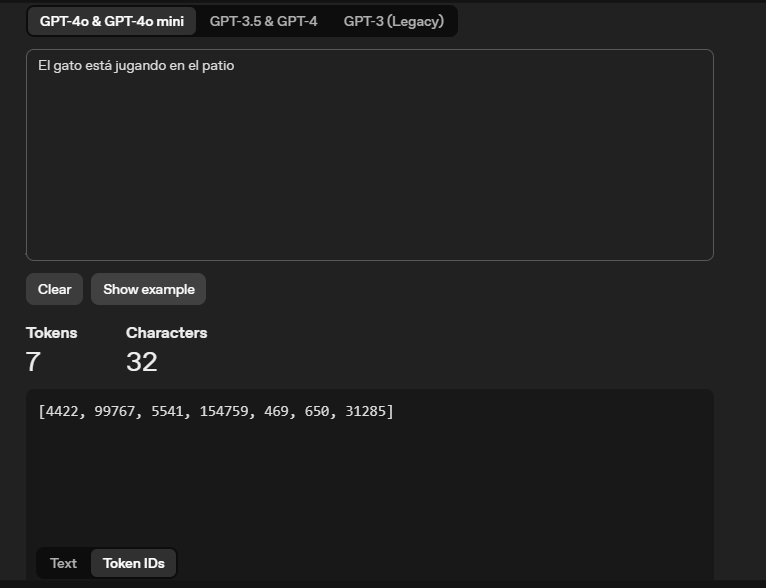 |
With all this said, what is the special component of these models and why does it make them so successful? The special component of these models can be summed up in one word: Attention or also called Transformer model. The language model pays "attention" to all the context passed to it as input through mechanisms called attention mechanisms. These work on embeddings, which are the semantic representation of text through vectors. That is, the model manages to understand the context of a sentence, paragraph or huge text by being able to relate the meanings of words that may be dispersed throughout the text.
Simple example: In the sentence "I saw the man with the telescope", the attention mechanisms help the model understand whether the "man" has the "telescope" or if the "telescope" is used to see the "man". This allows language models to unlock a large number of capabilities to understand and generate text optimally and accurately.
The following diagram visually represents the complete functioning of these models: from the input (prompt), the tokenization of the text, the generation of embeddings, the execution of the attention mechanism by the Transformer model, the prediction of tokens and finally the conversion back to text. This entire process is called inference:
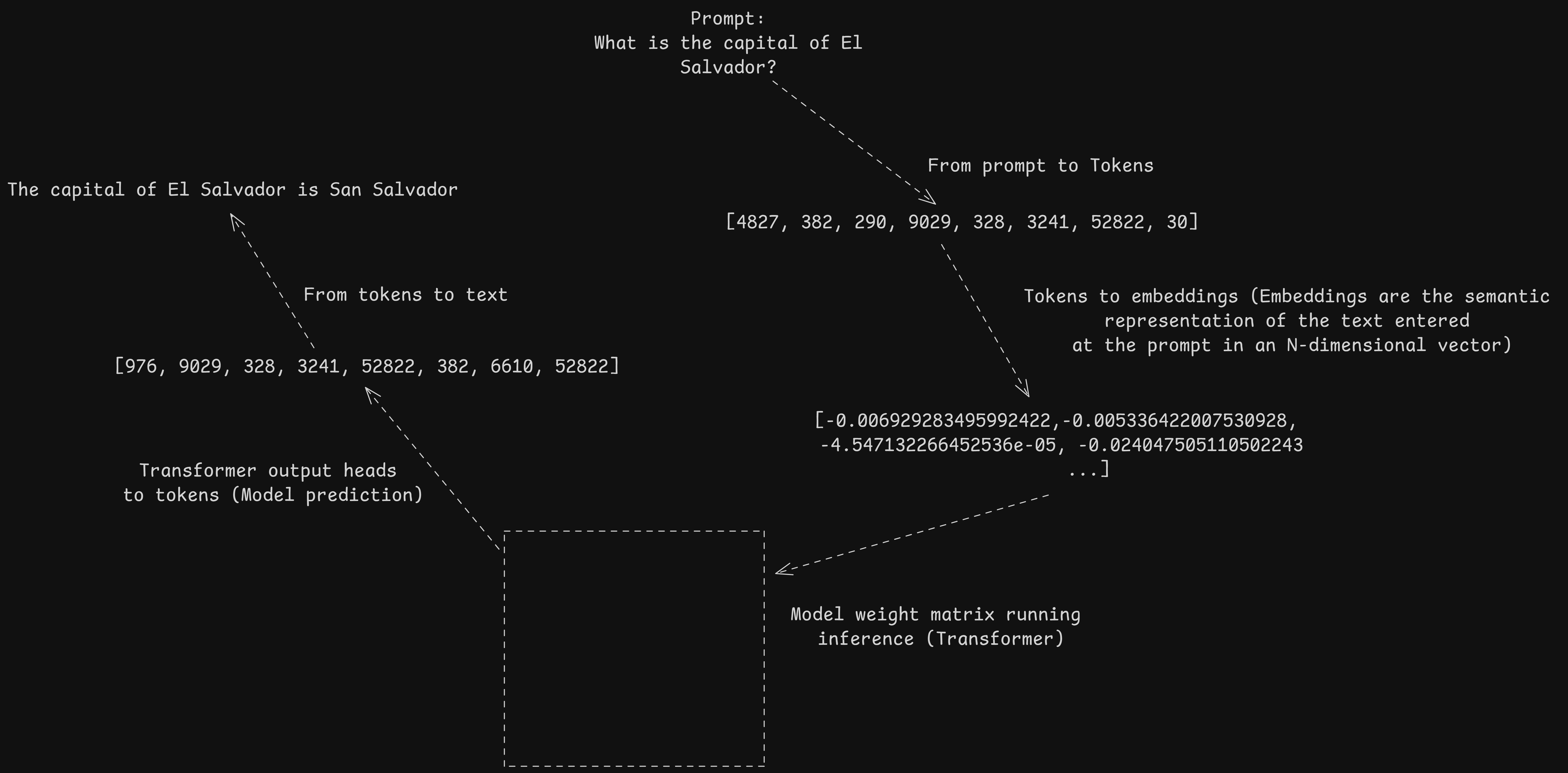
Vision-Language Models (VLMs) work similarly to LLMs, but incorporate an additional modality: vision. These models must understand both the text and images provided as input, relate them to each other, and determine which information is most relevant within the input sequence.
For example, models from the Qwen2.5-VL family use an architecture with two specialized encoders: one for images and one for text. The image encoder processes the visual input and converts it into visual embeddings, which are later concatenated with the textual embeddings generated by the text encoder. This combination allows the model to process both modalities in a unified way and understand the context between them through the Transformer.
The following diagram visually represents the complete functioning of these models: from the input of the 2 modalities (text and image), the processing done by each of the encoders, how the visual and textual embeddings are concatenated for the Transformer input, the execution of the attention mechanism, the prediction of tokens and finally the conversion back to text.
It was previously mentioned that both LLMs and VLMs are trained with large amounts of text, or text and images respectively, but that training, also known as "Pre-training" in English, is for the task of predicting the next word or token. These models are called base models, from which models then emerge such as GPT-5 (used in ChatGPT), LLaMA, Qwen. These models cannot yet act as a chatbot, which is what we mostly know about how these models work.
Generally, to achieve this behavior, fine-tuning or fine adjustment techniques are employed, where we start from one of these base models and train it to learn how to interact as a chatbot, either with large pre-processed and curated datasets so that there is no sensitive information, false data, unwanted behaviors, etc.
To do fine-tuning there are many techniques, but we are going to focus on the 3 most well-known, which are Full Fine-Tuning, LoRA and QLoRA.
It consists of taking the base model and training it by updating all its weights with the previously prepared dataset. This technique is where you get 100% of the model's capacity, but it also has drawbacks related to the hardware needed to run this training.
For example, to train a 3B parameter LLM we would need a NVIDIA A100 80GB GPU or 2 NVIDIA A100 40GB. Typical hyperparameters would be:
This means that with a batch_size of 2 and gradient_accumulation_steps of 16, the model would effectively train with 32 examples before each weight update.
Given the above problem, in 2021 the paper LoRA: Low-Rank Adaptation of Large Language Models came out, where instead of training the entire model, it proposes the idea of leaving the base model frozen, that is, its weights are not updated, and only building an adapter for the base model that will be trained with the entire dataset. With this simple idea, we gain much lower hardware requirements, being able to train the 3B model on GPUs with 24GB of VRAM or less, achieving results very close to full fine-tuning in most tasks. Consumer GPUs like the NVIDIA RTX 3090 and 4090 are completely capable of training a 3B model without problems.
Although LoRA was a great advance in reducing the requirements of these models, models of 20B to 70B parameters still needed GPUs like the NVIDIA A100. This led to the paper QLoRA: Efficient Finetuning of Quantized LLMs being released in 2023, which added another innovation: quantizing the base models to train them.
What is quantization? It is reducing the number of bits used to represent each parameter of the model, going from 32 or 16 bits to only 4 bits. This drastically reduces memory usage, although with a small loss of precision. What's interesting is that this loss is usually minimal: a 70B quantized model is still better than a 7B model with full precision, even occupying the same amount of memory.
The process is: first we quantize the large model (for example 70B) and then apply LoRA to it. Since the quantized model uses much less memory, LoRA is also smaller. This allowed researchers to train a 65B model on a 48GB VRAM GPU, when before they would have needed multiple high-end GPUs.
With all this in mind, in the following video all these techniques are represented visually.
I decided to create my own fine-tuning framework to have a much easier and faster way to launch trainings of the most well-known models, such as the distilled versions of DeepSeek-R1, the open-source code models from OpenAI GPT-OSS-20B and GPT-OSS-120B, and the models from the Qwen-VL family for training vision and language models.
Since for most use cases these models are the preferred ones to train, and with Kronos I standardized and optimized the pipelines for each one, allowing launching the training of DeepSeek-R1, GPT-OSS-20B and Qwen2.5-VL to be almost identical, and also allowing monitoring the training with wandb (only changing the way data is processed, which is anyway already standardized for both language-only models and vision-language models):
GPT-OSS-20B:
if __name__ == "__main__": dataset = Dataset(name="Aquiles-ai/Medical-Reasoning", size="large", tokenizer_name="huihui-ai/Huihui-gpt-oss-20b-BF16-abliterated-v2")
trainer = KronosTrainGPTOSS( model_name="huihui-ai/Huihui-gpt-oss-20b-BF16-abliterated-v2", dataset_size="large", dataset=dataset, wandbkey="", max_seq_length=1024, lora_r=16, lora_alpha=32, load_in_4bit=False, batch_size=2, gradient_accumulation_steps=32, max_steps=350, eval_steps=50)
trainer.train()DeepSeek-R1-Distill
if __name__ == "__main__": dataset = Dataset("Aquiles-ai/Medical-Reasoning", size="large", )
trainer = KronosTrainDeepSeek( model_size="r1-0528-qwen3-8b-abliterated", dataset=dataset, wandbkey="", lora_r=16, lora_alpha=32, lora_dropout=0.05, max_steps=575, max_seq_length=2048, eval_steps=115 )
trainer.train()Qwen2.5-VL
if __name__ == "__main__": dataset = Dataset("HuggingFaceM4/WebSight", size="small", subset="v0.2", max_rows=10000)
trainer = KronosTrainQwen2_5VL("Qwen/Qwen2.5-VL-3B-Instruct", dataset_size="small", dataset=dataset, wandbkey="", lora_r=8, lora_alpha=16, max_steps=438, eval_steps=120)
trainer.train()Now we are going to do fine-tuning for 2 very specific and specialized use cases: training a model that can reason about complex medical cases, and another that can convert screenshots of user interfaces into functional HTML/CSS code.
We will see datasets, configurations, training times and real results obtained with accessible GPUs. For all this, we are going to use Kronos as the training framework and the lightning.ai platform as the GPU provider.
For the medical reasoning model called Asclepio (after the Greek god of medicine), we are going to use as base model huihui-ai/DeepSeek-R1-0528-Qwen3-8B-abliterated, which is an 8B parameter model accessible with an NVIDIA L4 24GB, which is the GPU we are going to use. We are going to use an "abliterated" version (uncensored), because medical data can contain graphic descriptions of wounds, invasive procedures and sensitive clinical cases that require unrestricted processing.
For the dataset we will use Aquiles-ai/Medical-Reasoning, a medical reasoning dataset that combines three high-quality sources and is formatted to follow the Chain of Thought paradigm, where the model explains its reasoning step by step before giving the final answer.
Dataset preprocessing:
The Aquiles-ai/Medical-Reasoning dataset uses the Hermes format (with roles system, human, gpt) and includes reasoning blocks marked with **<thinking>:**. Kronos automatically handles:
user, assistant)**<thinking>:** and reformatting it to <think>...</think> (native DeepSeek-R1 format)All this is done with a simple call:
dataset = Dataset( name="Aquiles-ai/Medical-Reasoning", size="large", # ~70K examples train_eval_split=0.1)Now to launch the fine-tuning of Asclepio we need to configure some key LoRA hyperparameters:
For a medical reasoning task, training steps should be above 450 so that the model sees an acceptable amount of examples and can learn from them. I decided to leave it at 575 steps: neither too long nor too short. The eval_steps are configured every 115 training steps, which allows us to monitor whether there is overfitting or underfitting. It's recommended that the training loss and evaluation loss follow similar trends.
trainer = KronosTrainDeepSeek( model_size="r1-0528-qwen3-8b-abliterated", dataset=dataset, wandbkey="", lora_r=16, lora_alpha=32, lora_dropout=0.05, max_steps=575, max_seq_length=2048, eval_steps=115)
trainer.train()The following screenshot shows memory usage during training:
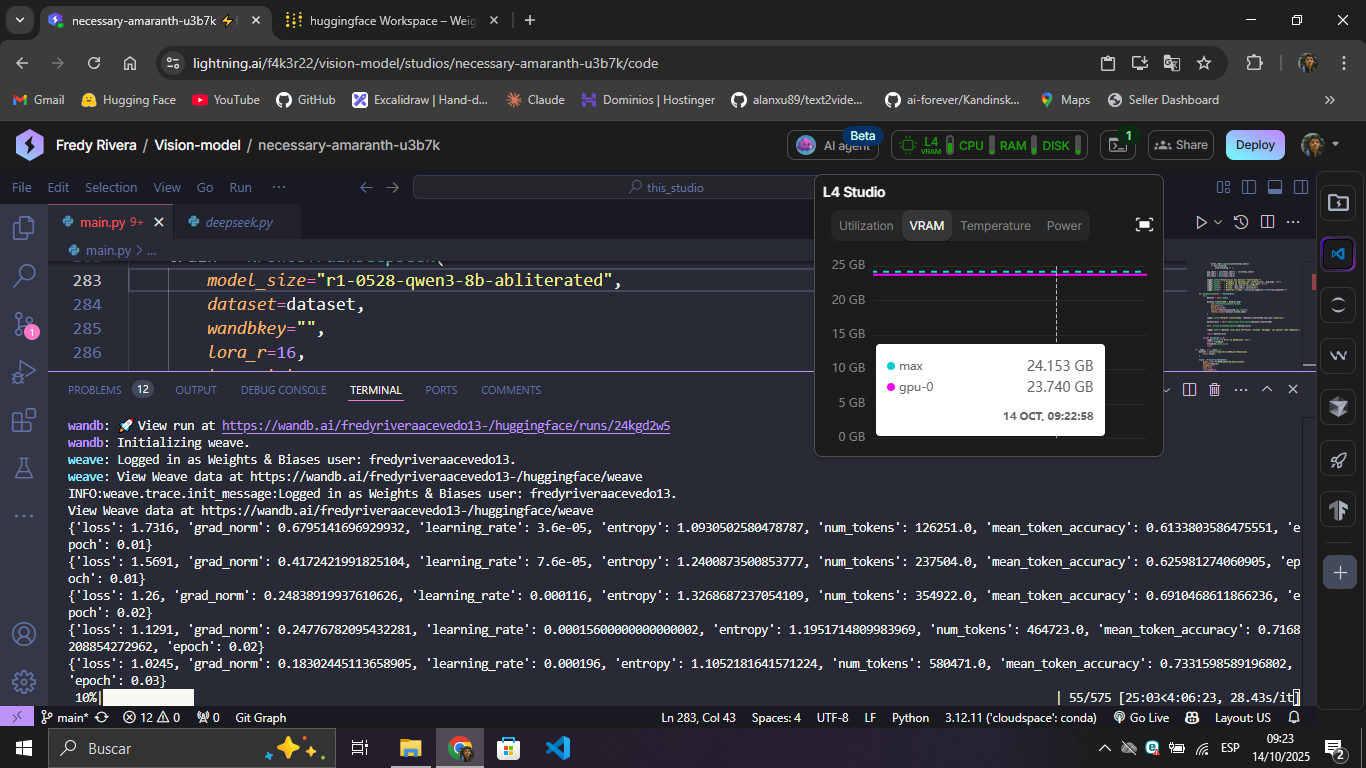
The following screenshot shows the training duration and hardware used:
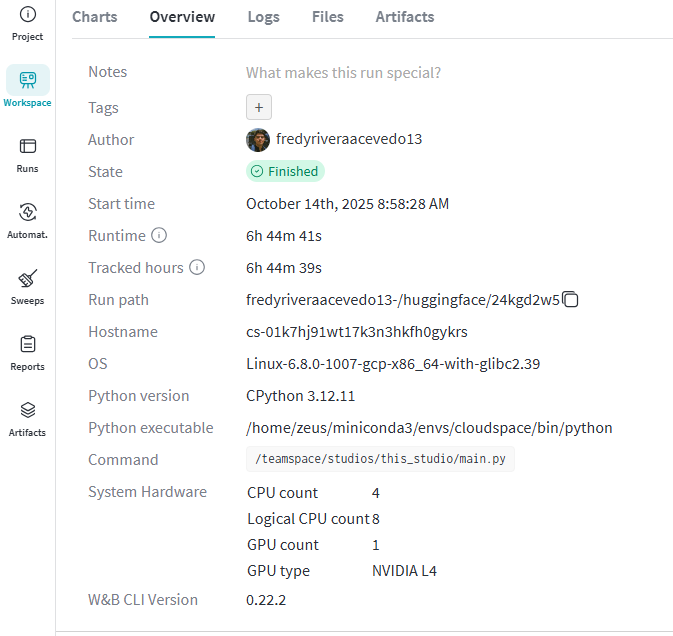
As shown in the previous screenshot, the training took 6 hours and 44 minutes. Given that the cost per hour of the NVIDIA L4 is $0.48, the entire training cost me $3.23 dollars.
| Metric | Initial Value | Final Value | Observation |
|---|---|---|---|
| Train Loss | ~1.6 | ~0.85 | Rapid convergence in first 200 steps |
| Token Accuracy | ~62% | ~76.9% | Stable after initial warmup |
| Learning Rate | 0.00015 | ~0.00005 | Linear decay after warmup |
| Total Steps | - | 575 | No signs of overfitting |
The model achieved 76.9% accuracy in token prediction, demonstrating that it effectively learned the patterns of medical reasoning from the dataset. The loss stabilized around 0.88, indicating successful convergence.
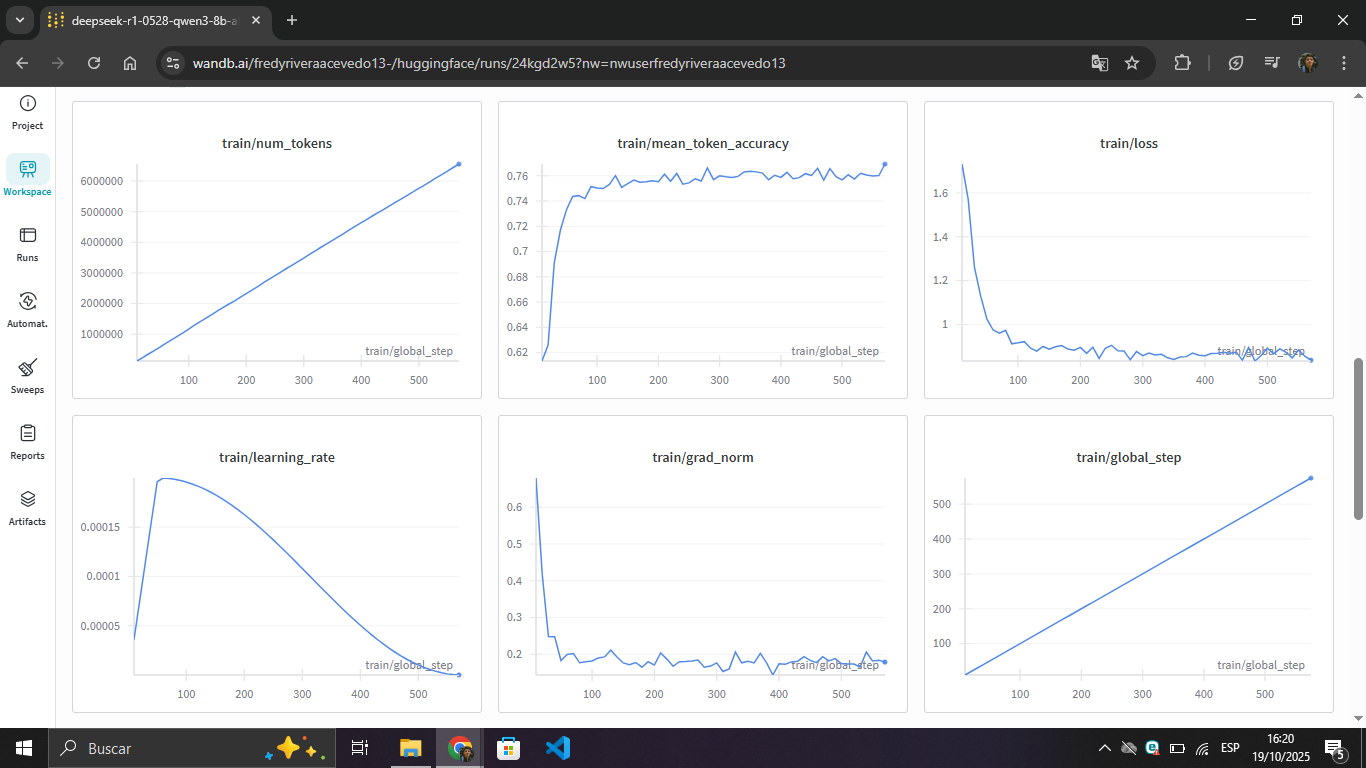
Evaluation metrics:
The evaluation set validated the model's generalization ability:
| Metric | Initial Eval | Final Eval | Final Train | Difference |
|---|---|---|---|---|
| Loss | 0.96 | 0.92 | 0.88 | +0.04 ✓ |
| Accuracy | 75.4% | 76.3% | 76.9% | -0.6% ✓ |
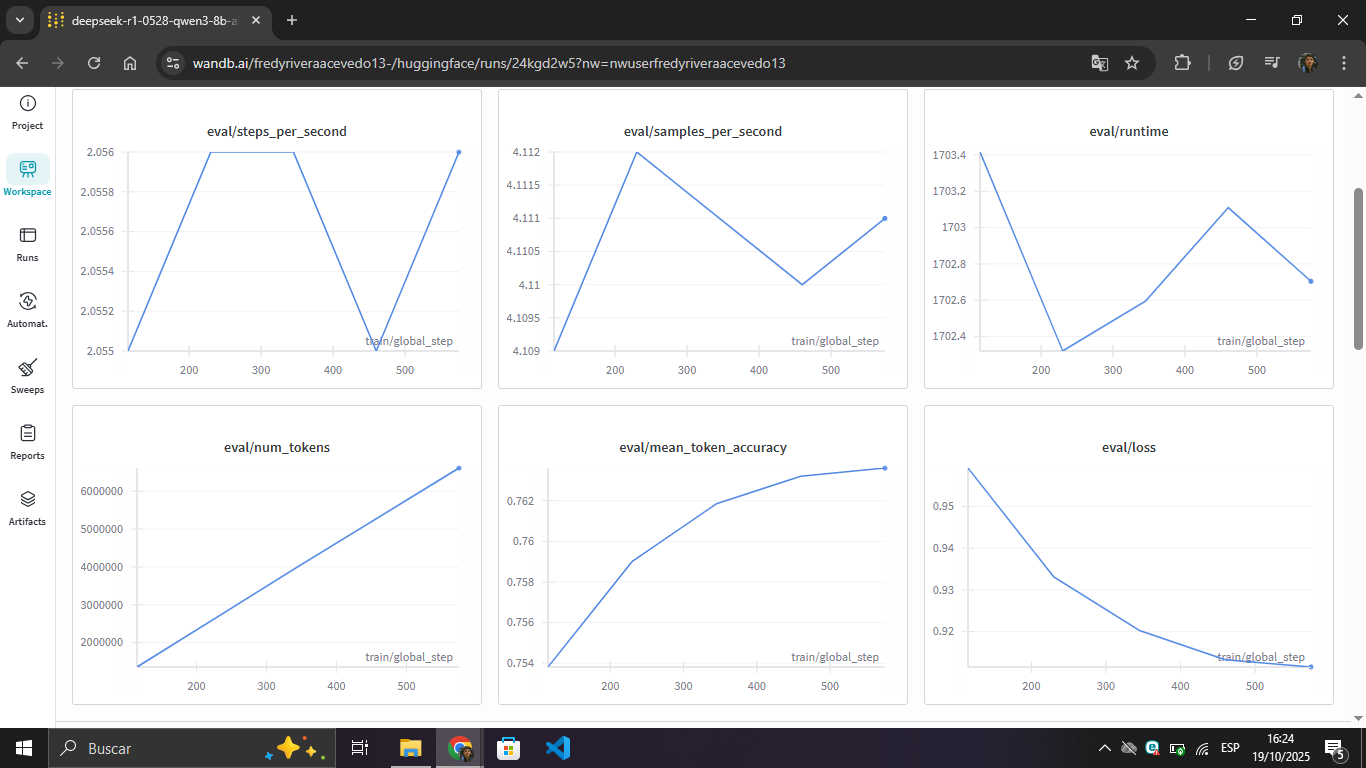
Interpretation: The minimal difference between train and eval (0.04 in loss, 0.6% in accuracy) indicates that there is no overfitting. The model learned generalizable patterns of medical reasoning instead of memorizing the training dataset.
For the code generation model from a screenshot, we are going to use as base model Qwen/Qwen2.5-VL-3B-Instruct, which is a 3B parameter model from the Qwen-VL family of models specialized in Vision-Language.
For the dataset we will use HuggingFaceM4/WebSight, a synthetic dataset that contains HTML/CSS codes representing websites in English generated synthetically, each one accompanied by a corresponding screenshot.
Dataset preprocessing:
The dataset presents the format of image (the screenshot of the generated web), text (the code of the generated web) and llm_generated_idea (which is a description given by an LLM of the generated website), for example: "This site is a cosmetics store".
Kronos requires that the multimodal dataset we pass to it has this format:
{ "messages": [ { "role": "system", "content": [ { "type": "text", "text": "You are an assistant that describes images." } ] }, { "role": "user", "content": [ { "type": "image", "image" : PIL.Image }, { "type": "text", "text": "What is in this image?" } ] }, { "role": "assistant", "content": [ { "type": "text", "text": "I see a dog playing in a park at sunset." } ] } ]}In our dataset class we will preprocess the data, so that the dataset we send is like this, and Kronos will train our model without problem:
{ "role": "user", "content": [ { "type": "image", "image": Image.PIL, }, { "type": "text", "text": "Generate the HTML/CSS code for this webpage screenshot.", } ]},{ "role": "assistant", "content": [ { "type": "text", "text": "I see a website of 'Here would go the content of the llm_generated_idea column from the dataset', \nthe code would be: \n'Here would go the content of the text column from the dataset'" } ]}So that when calling the dataset it is this:
dataset = Dataset("HuggingFaceM4/WebSight", size="small", subset="v0.2", # ~9K examples max_rows=10000)Now to launch the fine-tuning of Qwen2.5-VL-3B-Instruct-Img2Code we will configure the hyperparameters like this:
trainer = KronosTrainQwen2_5VL("Qwen/Qwen2.5-VL-3B-Instruct", dataset_size="small", dataset=dataset, wandbkey="", lora_r=8, lora_alpha=16, max_steps=438, eval_steps=120)
trainer.train()The following image shows the VRAM usage of the model when starting the training. At the end, the VRAM usage during training was around 23.7GB of VRAM because the dataset contained images and were much heavier in memory than a text-only dataset:
The following screenshot shows the training duration and hardware used:
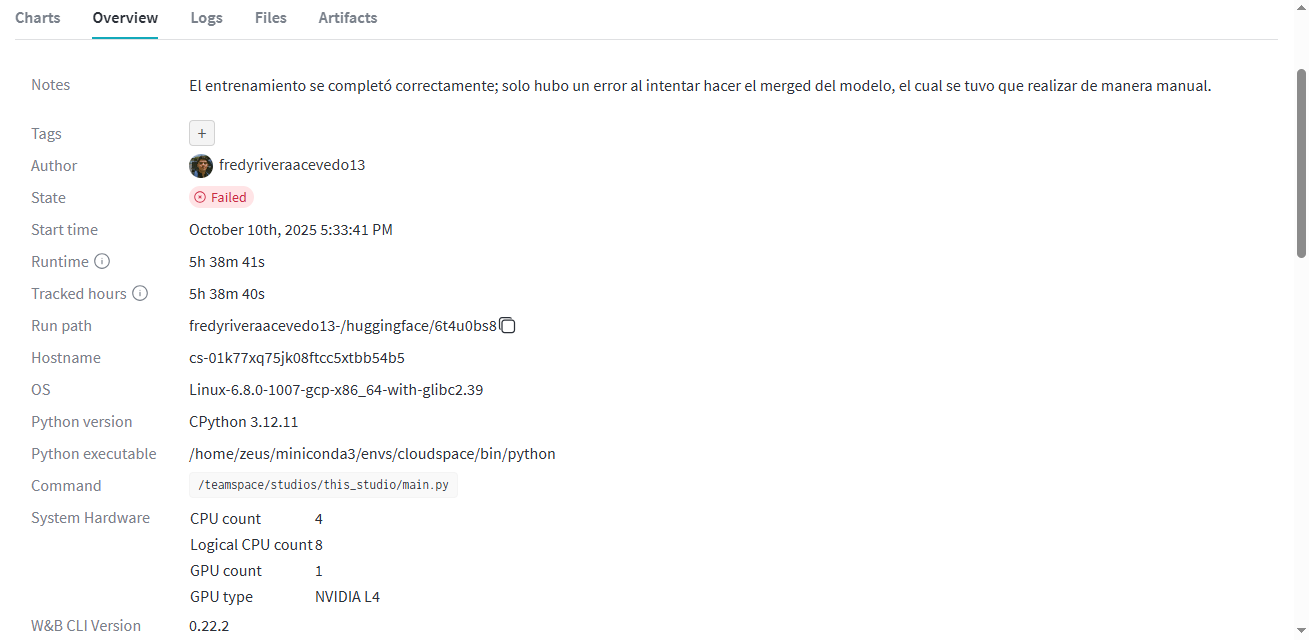
As shown in the previous screenshot, the training took 5 hours and 38 minutes. Given that the cost per hour of the NVIDIA L4 is $0.48, the entire training cost me $2.80 dollars. (As clarified previously, only the training cost is taken into account, not development or tests to find the optimal configuration)
| Metric | Initial Value | Final Value | Observation |
|---|---|---|---|
| Train Loss | ~0.6 | ~0.2 | Sharp decrease in first 100 steps |
| Token Accuracy | ~90% | ~94-96% | High variability during training |
| Learning Rate | 0.00015 | ~0.00005 | Linear decay after warmup |
| Gradient Norm | ~1-2 | ~0.5-1 | Some spikes up to 5, but controlled |
| Total Steps | - | 438 | Successful convergence |
The model achieved 94-96% accuracy in token prediction during training. The high variability in accuracy is normal in multimodal tasks (vision + language), as some screenshot-to-code examples are more complex than others. The loss stabilized around 0.2.
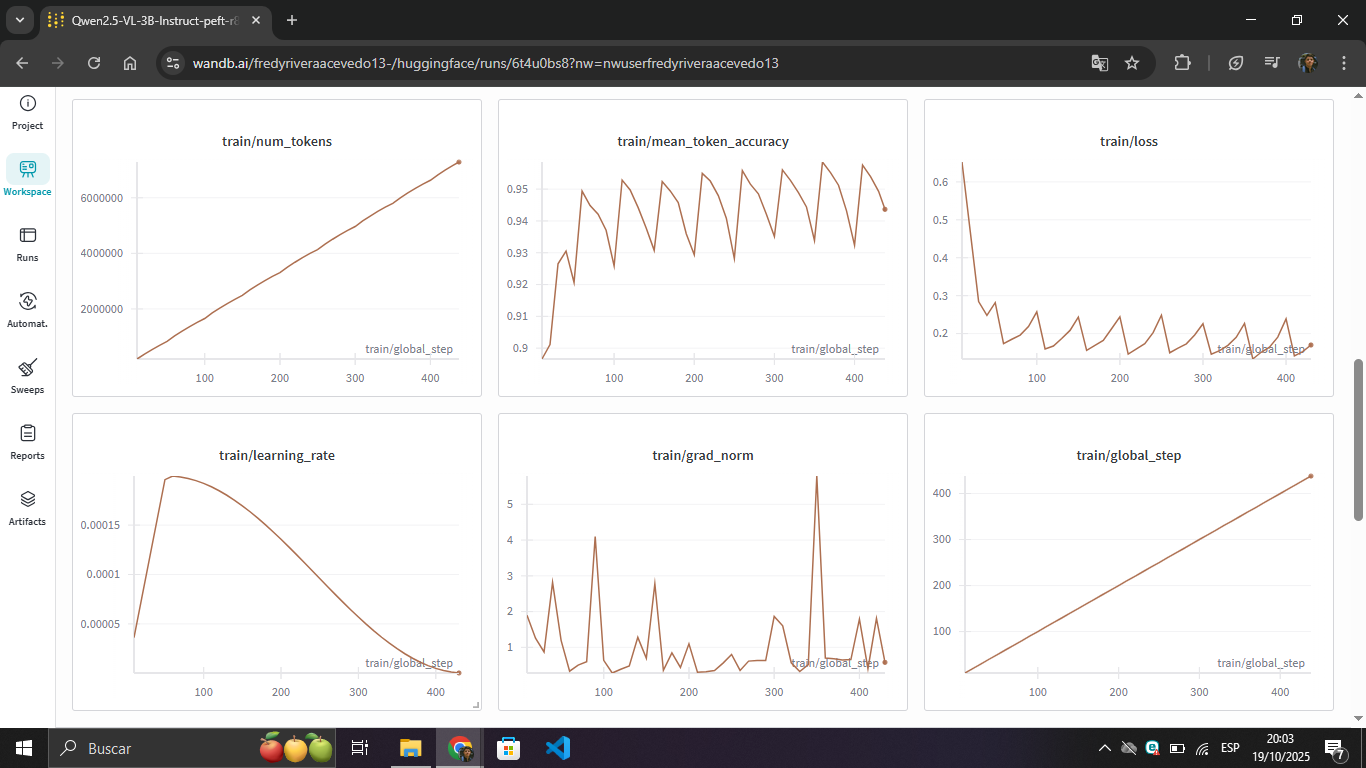
Evaluation metrics:
The evaluation set demonstrated excellent generalization capability:
| Metric | Initial Eval | Final Eval | Final Train | Difference |
|---|---|---|---|---|
| Loss | 0.2 | 0.185 | ~0.2 | +0.015 ✓ |
| Accuracy | ~94.1% | ~94.6% | ~94-96% | Similar ✓ |
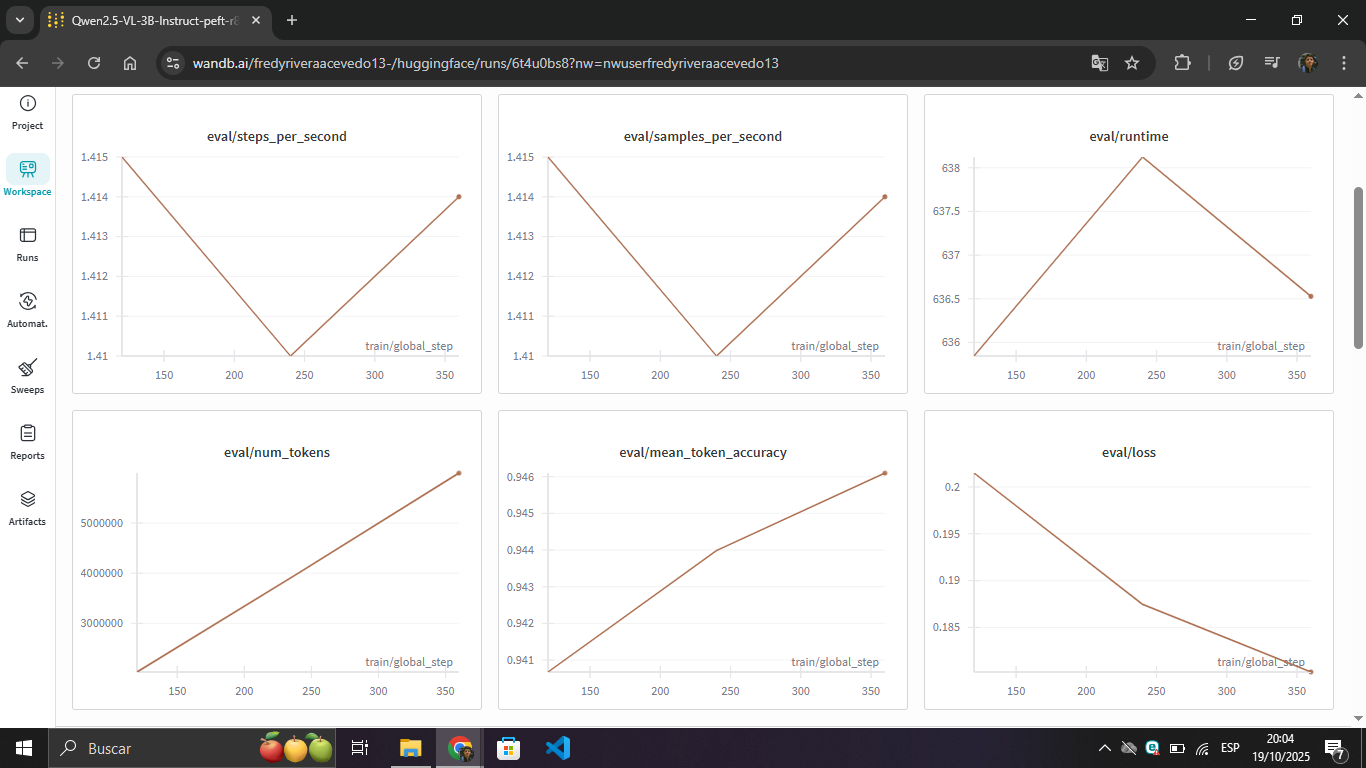
Interpretation: The model achieved 94.6% accuracy on the evaluation set for the screenshot-to-code task. The minimal difference in loss (~0.015) indicates excellent generalization. The stability of eval accuracy compared to the variability of train accuracy suggests that the model learned robust patterns of visual-to-code conversion.
Now that we have the trained models, the following videos show a demo from a chatbot-type playground to facilitate interaction:
Asclepio-8B
Qwen2.5-VL-3B-Instruct-Img2Code
Models, datasets and playground repository:
Papers, reference documentation and platforms used:
Contact: